SequoiaDB as a distributed database, based on self-developed native distributed storage engine, provides a comprehensive range of features and performance advantages.SequoiaDB supports complete ACID transactions, with elastic scaling, high concurrency and high availability characteristics, to provide enterprises with reliable data processing and storage solutions.
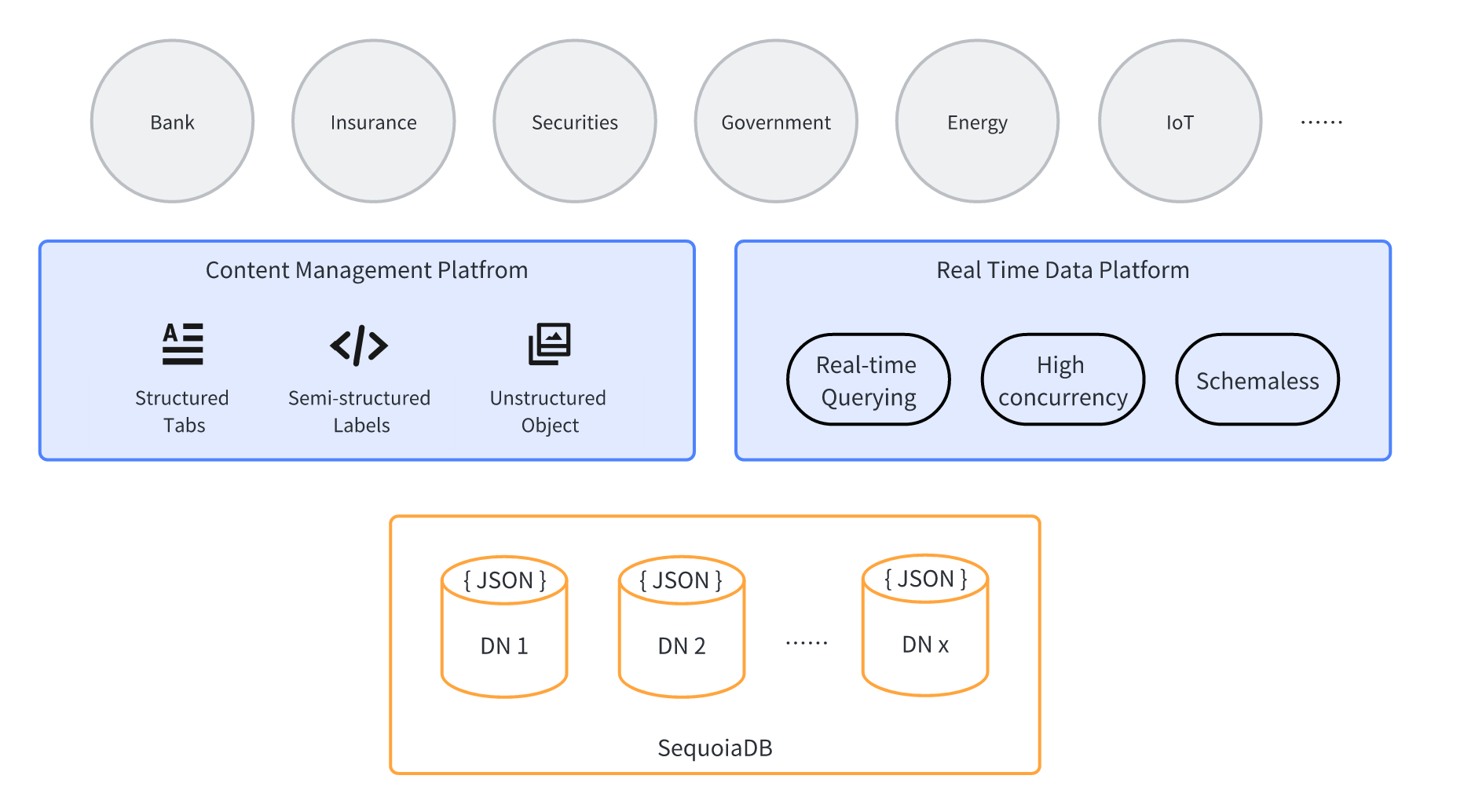
SequoiaDB is based on its semi-structured data format of document type JSON, and further forms Multi-Model multimodel data processing capability, which can support cross-structured, semi-structured and unstructured multimodel data processing. SequoiaDB provides SQL interface to facilitate the processing of structured data; JSON interface to handle semi-structured document-type JSON data; and S3 interface to handle unstructured object data, which makes SequoiaDB more flexible and efficient in dealing with different data types.
SequoiaDB not only provides compatibility with structured SQL query syntax and the ability to process unstructured S3 object data, but also provides real-time SQL query performance for trillions of data under >10,000 concurrent connections, which can be used to perform real-time SQL queries for trillions of data based on SequoiaDB, realizing unified management of unstructured data and structured data, and providing a unified way of managing both unstructured data and structured data for enterprises. A solution for unified management of unstructured and structured data.
SequoiaDB's outstanding performance and flexibility make it the database solution of choice for handling large-scale data, and it can be applied to various scenarios, such as historical data platforms, full-volume data platforms, real-time data middle-grounds, and content data management platforms, etc., to help enterprises optimize business efficiency and improve customer satisfaction.

Engine-level
Multi-modality
Native JSON API operations empower enterprise-level clients to enhance migration reliability and boost the learning efficiency of development personnel.
The compatibility with SQL protocol and S3 object data engine interface enables unified management of both unstructured and structured data.
Each engine offers MultiMaster support for multiple primary nodes, allowing on-demand online scalability of read and write performance.

Unafraid of Explosive
Data Growth
On-demand online scaling, ensuring continuous online availability of enterprise's complete content data
Supporting policy-based partition management and subdomain caching to enhance management efficiency and processing performance of massive data
Pooling storage layer resources, significantly reducing hardware and operational costs, with TCO being only one-third of traditional ECM.

Data Security
Supporting 3 to 7 configuration copies for different business scenarios
Providing unique data recovery service to avoid business losses caused by accident data deletion
Auditing data trails with clear and traceable records for system compliance