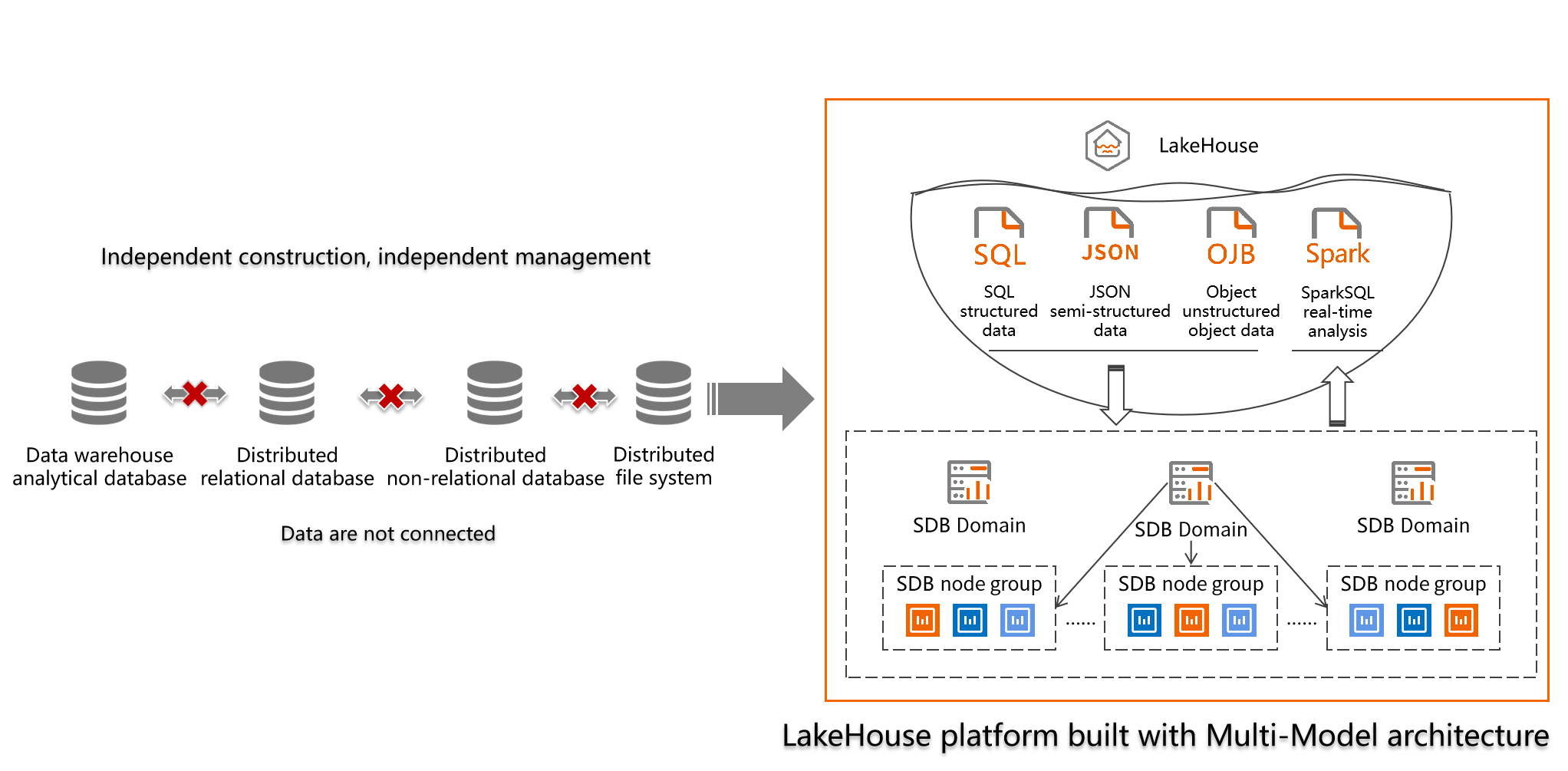
Based on SequoiaDB’s distributed Lakehouse database, SequoiaDP is a multi-modal platform that is compatible with engines of structured data, semi-structured data and unstructured object data. It features streaming computing, high-performance column storage analysis engines, cross-engine data ACID consistency, etc. It can be used to construct an integrated data platform with consistency and conduct real-time analysis with high performance simultaneously. SequoiaDP bridges the gulf between the data lake and the data warehouse with the data infrastructure built on only one data source for upper-layer applications. It helps our customers achieve data management improvement, cost reduction, operational efficiency advancement and user experience enhancement.

SequoiaDP truly realizes the integration of data lake and data warehouse to help enterprises build a whole new integrated data platform by bridging the gulf between the data lake and the data warehouse.The flexibility, diversity and rich ecology of the data lake are united with the enterprise data analytic capabilities of the data warehouse.

SequoiaDP can handily build a cross-engine data middle platform with the Lakehouse architecture to enable single coding for multiple engines. It helps our customers achieve data management improvement, cost reduction, operational efficiency advancement and user experience enhancement.

Engine-level
Multi-modality
Compatible with SDB API, SQL and S3 object interface
Providing the inclusive ecology of Apache Spark SQL for powerful data analysis performance
The rich multiple-engine compatibility helps to reduce R&D training costs and improve development efficiency

Lakehouse
Building on engine-level multi-modality to data lakes of structured, semi-structured, and unstructured data simultaneously
Using the same storage base for data deployment, data is written to multiple engines at once to avoid ETL
Deeply optimizing the Spark engine to conduct high-performance real-time analysis with great consistency

Upstream and
Downstream
Ecological
Supporting multiple ways of streaming data ingestion, including SQL, Flink, Spark Streaming, etc
Supporting multiple analysis tools, including Tableau, Power BI, FineReport, SmartBI, etc
Numerous best practices in banking, insurance, securities and various industries in the construction of the Lakehouse middle platform